📖프로세스 주소 공간
프로세스가 메모리를 할당 받으면, 자신만의 방법으로 메모리를 관리하기 위해 어떠한 구조로 관리하는데 이것이 프로세스 주소 공간
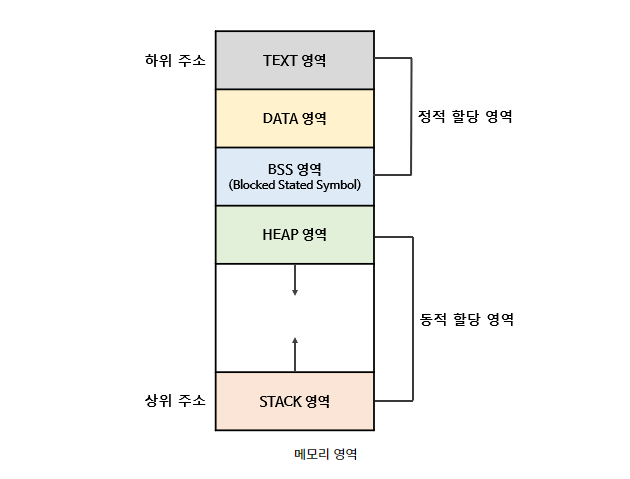
- 메모리가 한정적이기 때문에, 다양한 방법으로 메모리를 절약하려고 함
📖Stack 영역
- 함수의 호출과 관계되는 데이터(
지역 변수,매개 변수,리턴값)가 저장되는 영역 - 컴파일 타임에 크기가 결정되는 영역
- 각 함수는 LIFO 구조로 실행
- 함수의 호출과 함께 할당되고, 함수의 호출이 종료되면 소멸
- 메모리의 높은 주소에서 낮은 주소의 방향으로 할당
Stack Overflow
재귀 함수가 너무 깊게 호출되거나 지역변수가 너무 많아진다면 발생
📍Stack 영역은 컴파일 타임에 크기가 결정되므로 크기가 한정적이다
📖Heap 영역
- 동적 할당을 위한 메모리 영역
- 런타임에 크기가 결정되는 영역
- 주로 참조형 데이터(
클래스) 등의 데이터가 할당 - 메모리의 낮은 주소에서 높은 주소의 방향으로 할당
📖Data 영역
전역 변수나Static 변수같이 프로그램이 사용할 수 있는 데이터를 저장하는 영역전역 변수,static 변수를 참조하는 코드는 컴파일이 된 후에 Data 영역을 참조- 한 프로세스 내 여러 스레드가 있다면 Data 영역을 공유 ( ∴ 메모리 절약 가능)
- 프로그램의 실행 시 할당되고, 프로그램이 종료되면 소멸
Stack 영역과 Data 영역을 구분한 이유는 무엇일까?
- Stack 영역 구조의 특성과
전역 변수의 활용성을 위해 구분
- Stack 영역 : LIFO 구조로 함수의 흐름대로 실행
- Data 영역 :
전역함수,static 변수와 같은 데이터를 저장🔖각 스레드는 Data 영역을 공유하므로 메모리 절약 가능
📖Code(Text) 영역
- 프로그램을 실행시키는 실행 파일 내의 명령어들이 위치하는 영역
- 프로그램이 실행될 수 있도록 CPU가 해석 가능한 기계어 코드가 저장되어 있는 영역 → 프로그램이 수정되면 안되므로 Read-Only 상태로 저장
- 같은 프로그램으로 실행된 여러 프로세스는 동일한 코드를 가짐 ( ∴ 메모리 절약 가능)